The latest version of the Affymetrix Human Origins genotype dataset, published last month along with Lazaridis et al. 2014, is an awesome resource for population genetics (see here). However, it lacks Polish samples, which is a major drawback as far as this blogger is concerned.
Hopefully this oversight is corrected soon. In the meantime, I decided to include 15 Poles from the Eurogenes Project dataset in my copy of the Human Origins. But in order to do that I first had to impute around 460K genotypes for each of these people.
Imputing so many markers might sound pretty crazy, but it’s actually very doable, especially for genetically homogeneous groups with relatively low haplotype diversity, like the Polish population. I used BEAGLE 3.3.2 for the job, mostly because I’m familiar with it, but also because it’s quick and accurate.
My reference panel included 1090 individuals, most of them shared by Eurogenes and Human Origins, and just over 1 million markers. Only around 130K of the markers were shared by the two datasets, but well over 50% of the 1 million genotypes were observed in each of the Poles. This meant that I was imputing sporadically missing data, which is certainly a more sensible strategy than attempting to fill in long stretches of empty calls.
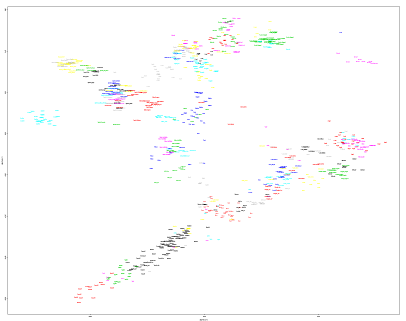
Everything seems to have worked out just fine, and the proof is in the pudding. Below are two Principal Component Analyses (PCA) featuring the Poles alongside 50 samples from the HGDP. The first PCA is based on observed genotypes, while the second on markers that were imputed into the Polish genomes. PCA are very sensitive to artifacts like genotyping errors, but as you can see, there’s very little difference between these results. Also, keep in mind that the SNPs used in the Human Origins were specifically chosen for population genetics, while those in the Eurogenes dataset come from chips mostly designed for commercial ancestry and medical work.
Also, here’s a PCA based on more than 300K SNPs, both observed and imputed in the Poles, featuring all of the West Eurasian samples from the filtered version of Human Origins, as well as the 15 Polish individuals. Note that the Poles cluster more or less between the Czechs and groups from the East Baltic region, and overlap most strongly with Belarusians, which makes sense.
Citations… Brian L. Browning, Sharon R. Browning, A Unified Approach to Genotype Imputation and Haplotype-Phase Inference for Large Data Sets of Trios and Unrelated Individuals, AJHG, Volume 84, Issue 2, p210–223, 13 February 2009, DOI: http://dx.doi.org/10.1016/j.ajhg.2009.01.005 Lazaridis et al., Ancient human genomes suggest three ancestral populations for present-day Europeans, Nature, 513, 409–413 (18 September 2014), doi:10.1038/nature13673 Source Polish and European population genetics and modern physical anthropology.









Комментариев нет:
Отправить комментарий